山东大学学报 (工学版) ›› 2019, Vol. 49 ›› Issue (2): 34-41.doi: 10.6040/j.issn.1672-3961.0.2018.197
高明霞( ),李经纬
),李经纬
Mingxia GAO(),Jingwei LI
摘要:
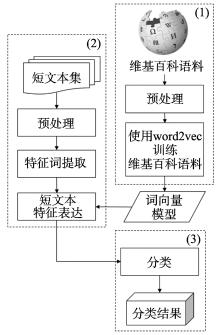
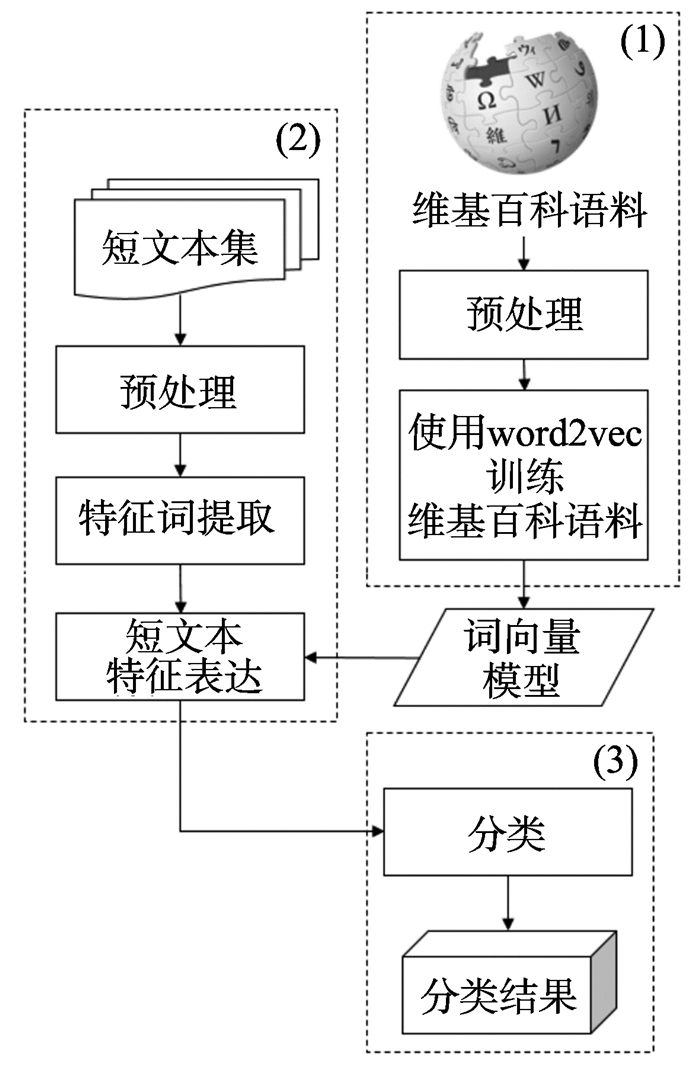
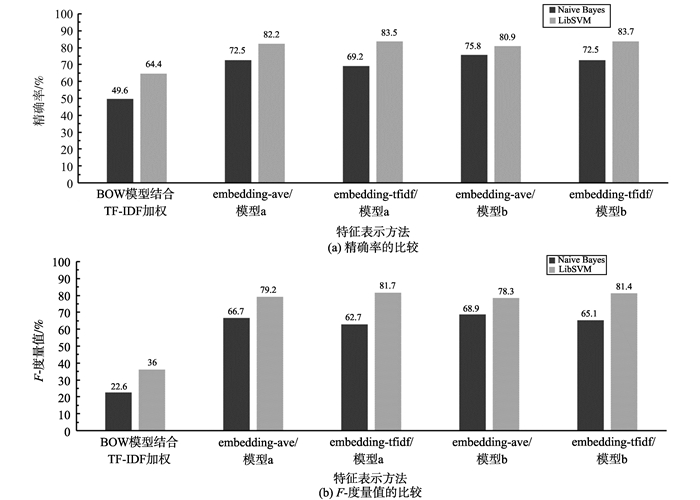
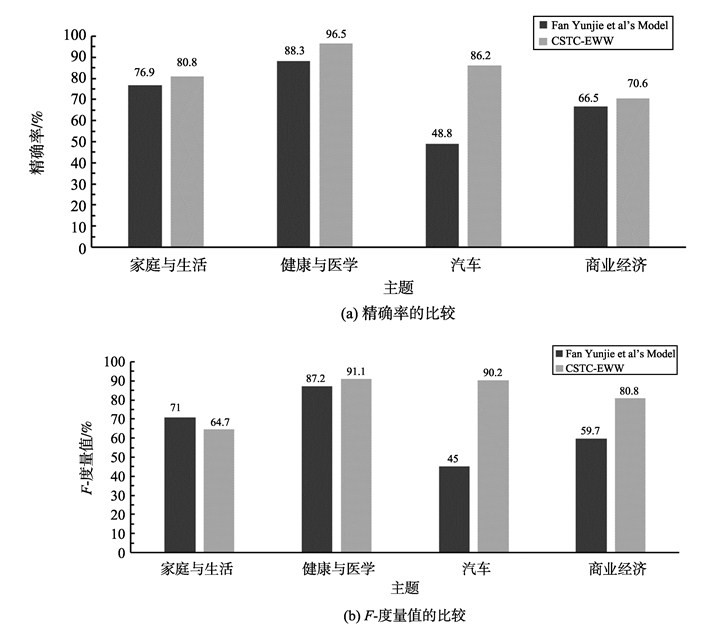
针对受字数限定影响的文本特征表达能力弱成为短文本分类中制约效果的主要问题,提出基于word2vec维基百科词模型的中文短文本分类方法(chinese short text classification method based on embedding trained by word2vec from wikipedia, CSTC-EWW),并针对新浪爱问4个主题的短文本集进行相关试验。首先训练维基百科语料库并获取word2vec词模型,然后建立基于此模型的短文本特征,通过SVM、贝叶斯等经典分类器对短文本进行分类。试验结果表明:本研究提出的方法可以有效进行短文本分类,最好情况下的F-度量值可达到81.8%;和词袋(bag-of-words, BOW)模型结合词频-逆文件频率(term frequency-inverse document frequency, TF-IDF)加权表达特征的短文本分类方法以及同样引入外来维基百科语料扩充特征的短文本分类方法相比,本研究分类效果更好,最好情况下的F-度量提高45.2%。
中图分类号:
| 1 | 刘英涛.短文本分类研究[D].重庆:重庆理工大学, 2016. |
| LIU Yingtao. Research on short text classification[D]. Chongqing: Chongqing University of Technology, 2016. | |
| 2 | METZLER D, DUMAIS S, MEEK C. Similarity measures for short segments of text[C]//Processdings of AAAI Conference on Artificial Intelligence. Heidelberg Berlin Germany: Springer-Verlag, 2007: 16-27. |
| 3 | ZELIKOWITZ S , TRANSDUCTIVE M F . Learning for short-text classification problem using latent semantic indexing international[J]. Journal of Pattern Recognition and Artificial Intelligence, 2005, 19 (2): 143- 163. |
| 4 | 杨超群.基于自身特征的短文本分类研究[D].合肥:合肥工业大学, 2016. |
| YANG Chaoqun. Research on short text classification based on its own features[D]. Hefei: Hefei University of Technology, 2016. | |
| 5 | 范云杰,刘怀亮.基于维基百科的中文短文本分类研究[D].西安:西安电子科技大学, 2013. |
| FAN Yunjie, LIU Huailiang. Research on Chinese short text classification based on wikipedia[D]. Xi'an: Xidian University, 2013. | |
| 6 | 刘婧姣,张素智.基于语义的短文本分类算法研究[D].郑州:郑州轻工业学院, 2013 |
| LIU Jingjiao, ZHANG Suzhi. The study of short text classification algorithm based on semantic[D]. Zhengzhou: Zhengzhou University of Light Industry, 2013. | |
| 7 | 蔡志威,闵华清.基于概念的短文本分类[D].广州:华南理工大学, 2016. |
| CAI Zhiwei, MIN Huaqing. Concept-based short text classification[D]. Guangzhou: South China University of Technology, 2016. | |
| 8 |
李锐, 张谦, 刘嘉勇. 基于加权word2vec的微博情感分析[J]. 通信技术, 2017, 50 (3): 502- 506.
doi: 10.3969/j.issn.1002-0802.2017.03.021 |
|
LI Rui , ZHANG Qian , LIU Jiayong . Microblog sentiment analysis based on weighted word2vec[J]. Communications Technology, 2017, 50 (3): 502- 506.
doi: 10.3969/j.issn.1002-0802.2017.03.021 |
|
| 9 | 董文.基于LDA和word2vec的推荐算法研究[D].北京:北京邮电大学, 2015. |
| DONG Wen. Research of recommendation algorithm based on LDA and word2vec[D]. Beijing: Beijing University of Posts and Telecommunications, 2015. | |
| 10 | 闭炳华. 基于word2vec的数字图书馆本体构建技术研究[J]. 现代电子技术, 2016, 39 (15): 90- 94. |
| BI Binghua . Research on digital library ontology construction technology based on word2vec[J]. Modern Electronics Technique, 2016, 39 (15): 90- 94. | |
| 11 |
赵飞, 周涛, 张良, 等. 维基百科研究综述[J]. 电子科技大学学报, 2010, 39 (3): 321- 334.
doi: 10.3969/j.issn.1001-0548.2010.03.001 |
|
ZHAO Fei , ZHOU Tao , ZHANG Liang , et al. Research progress on Wikipedia[J]. Journal of University of Electronic Science and Technology of China, 2010, 39 (3): 321- 334.
doi: 10.3969/j.issn.1001-0548.2010.03.001 |
|
| 12 | HINTON G E. Learning distributed representations of concepts[C]//Proceedings of the Eighth Annual Conference of the Cognitive Science Society. Hillsdale, USA: Erlbaum, 1986: 1-12. |
| 13 | BENGIO Y , DUCHARME R , VINCENT P , et al. A neural probabilistic language model[J]. The Journal of Machine Learning Research, 2003, 3, 1137- 1155. |
| 14 | MIKOLOV T , SUTSKEVER I , CHEN K , et al. Distributed representations of words and phrases and their compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26, 3111- 3119. |
| 15 |
熊富林, 邓怡豪, 唐晓晟. word2vec的核心架构及其应用[J]. 南京师范大学学报(工程技术版), 2015, (1): 43- 48.
doi: 10.3969/j.issn.1672-1292.2015.01.008 |
|
XIONG Fulin , DENG Yihao , TANG Xiaosheng . The Architecture of word2vec and its applications[J]. Journal of Nanjing Normal University(Engineering and Technology Edition), 2015, (1): 43- 48.
doi: 10.3969/j.issn.1672-1292.2015.01.008 |
|
| 16 | 唐明, 朱磊, 邹显春. 基于word2Vec的一种文档向量表示[J]. 计算机科学, 2016, 43 (6): 214- 217. |
| TANG Ming , ZHU Lei , ZOU Xianchun . Document vector representation based on word2vec[J]. Computer Science, 2016, 43 (6): 214- 217. | |
| 17 | 陆远蓉. 使用数据挖掘工具Weka[J]. 电脑知识与技术, 2008, 1 (6): 14- 16, 19. |
| LU Yuanrong . Using weka as data mining tool[J]. Computer Knowledge and Technology, 2008, 1 (6): 14- 16, 19. | |
| 18 |
汪海燕, 黎建辉, 杨风雷. 支持向量机理论及算法研究综述[J]. 计算机应用研究, 2014, 31 (5): 1281- 1286.
doi: 10.3969/j.issn.1001-3695.2014.05.001 |
|
WANG Haiyan , LI Jianhui , YANG Fenglei . Overview of support vector machine analysis and algorithm[J]. Application Research of Computers, 2014, 31 (5): 1281- 1286.
doi: 10.3969/j.issn.1001-3695.2014.05.001 |
|
| 19 | YANG Y. A re-examination of text categorization methods[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval. New York, USA: ACM, 1999: 42-49. |
| 20 | 奉国和, 郑伟. 国内中文自动分词技术研究综述[J]. 图书情报工作, 2011, 55 (2): 41- 45. |
| FENG Guohe , ZHENG Wei . Review of Chinese automatic word segmentation[J]. Library and Information Service, 2011, 55 (2): 41- 45. |
| [1] | 沈冀,马志强,李图雅,张力. 面向短文本情感分析的词扩充LDA模型[J]. 山东大学学报(工学版), 2018, 48(3): 120-126. |
| [2] | 闫盈盈,黄瑞章,王瑞,马灿,刘博伟,黄庭. 一种长文本辅助短文本的文本理解方法[J]. 山东大学学报(工学版), 2018, 48(3): 67-74. |
| [3] | 林江豪,周咏梅,阳爱民,陈锦. 基于词向量的领域情感词典构建[J]. 山东大学学报(工学版), 2018, 48(3): 40-47. |
| [4] | 邵发, 黄银阁, 周兰江, 郭剑毅, 余正涛, 张金鹏. 基于实体消歧的中文实体关系抽取[J]. 山东大学学报(工学版), 2014, 44(6): 32-37. |
| [5] | 王洪元,封磊,冯燕,程起才. 流形学习算法在中文文本分类中的应用[J]. 山东大学学报(工学版), 2012, 42(4): 8-12. |
| Viewed | ||||||||||||||||||||||||||||||||||||||||||||||||||
|
Full text 870
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
Abstract 3470
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
Cited |
|
|||||||||||||||||||||||||||||||||||||||||||||||||
| Shared | ||||||||||||||||||||||||||||||||||||||||||||||||||
| Discussed | ||||||||||||||||||||||||||||||||||||||||||||||||||
|