山东大学学报 (工学版) ›› 2020, Vol. 50 ›› Issue (2): 100-107.doi: 10.6040/j.issn.1672-3961.0.2019.424
严云洋1,2,3( ),杜晨锡1,2,刘以安2,高尚兵1
),杜晨锡1,2,刘以安2,高尚兵1
Yunyang YAN1,2,3(),Chenxi DU1,2,Yian LIU2,Shangbing GAO1
摘要:
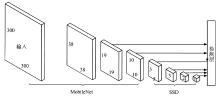
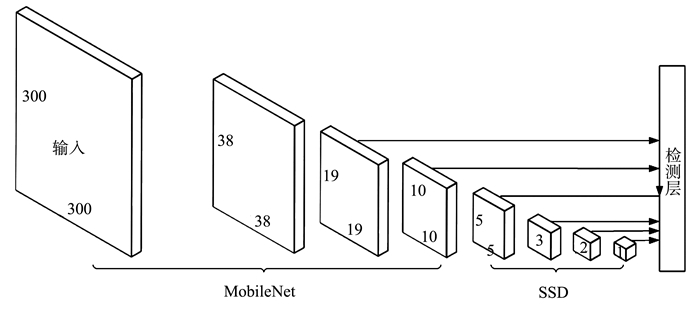
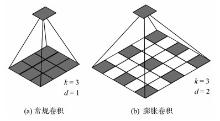
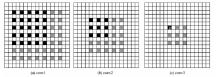
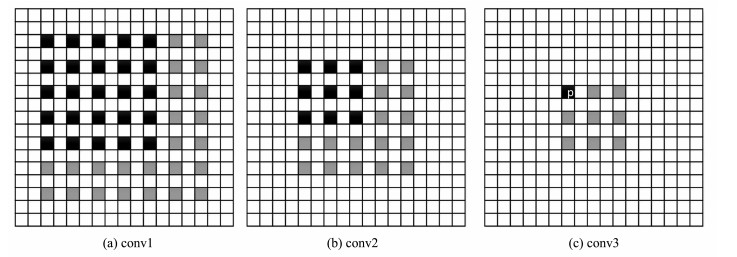
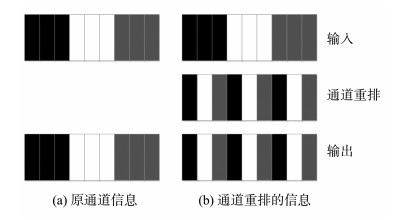
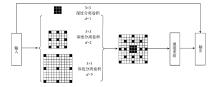
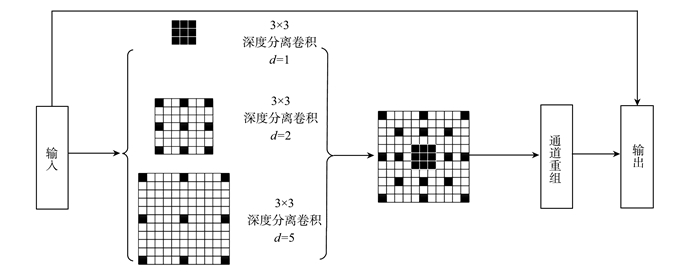
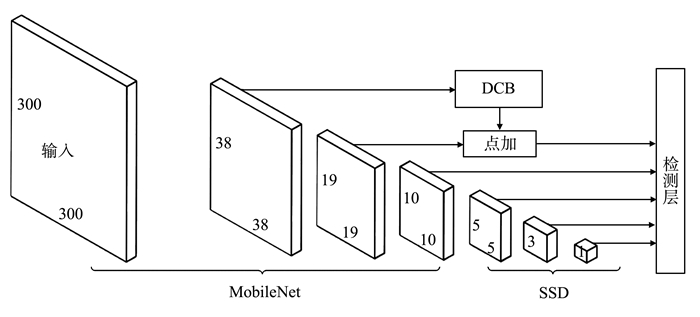
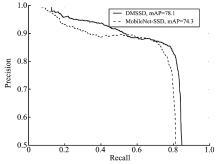
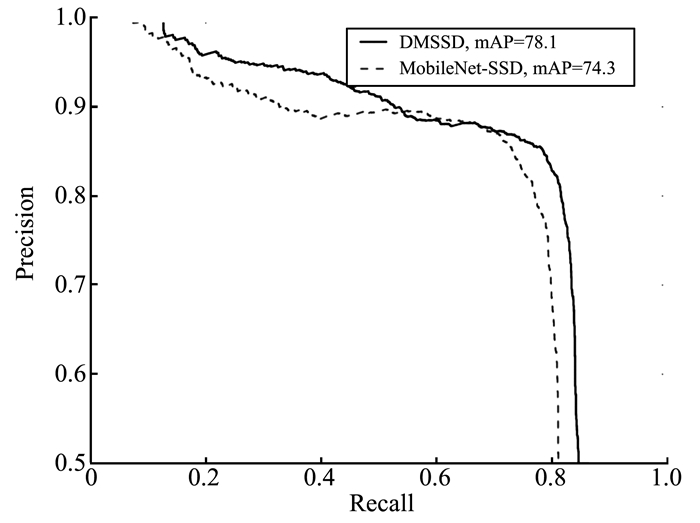
提出一种基于MobileNet的轻型火焰检测方法,基于深度分离卷积和膨胀卷积的膨胀卷积模块(dilated convolution block, DCB)扩增特征的感受野,加强特征语义信息,提高了视频火焰目标的检测率;优化SSD(Single Shot Multibox Detector)检测框架,提出了一种轻型的检测模型DMSSD(Dilated MobileNet-SSD)。在PASCAL VOC数据集和Bilkent大学VisiFire数据集上进行火焰检测试验,试验结果表明火焰检测的平均精度均值分别提升了1.7%和3.8%,火焰检测速度也可达80帧/s,具有较强的鲁棒性和实用性。
中图分类号:
| 1 | HOWARD A G, ZHU Menglong, CHEN Bo, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv: 1704.04861, 2017. https://arxiv.org/abs/1704.04861. |
| 2 | CHENG Yu, WANG Duo, ZHOU Pan, et al. A survey of model compression and acceleration for deep neural networks[J]. arXiv preprint arXiv: 1710.09282, 2017. https://arxiv.org/abs/1710.09282. |
| 3 | HAN Song, MAO Huizi, DALLY W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv: 1510.00149, 2015. https://arxiv.org/abs/1510.00149. |
| 4 | LUO Ping, ZHU Zhenyao, LIU Ziwei, et al. Face model compression by distilling knowledge from neurons[C]//Proceedings of 30th AAAI Conference on Artificial Intelligence. Menlo Park, USA: Association for the Advancement of Artificial Intelligence, 2016: 3560-3566. |
| 5 | JADERBERG M, VEDALDI A, ZISSERMAN A. Speeding up convolutional neural networks with low rank expansions[J]. arXiv preprint arXiv: 1405.3866, 2014. https://arxiv.org/abs/1405.3866. |
| 6 | SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE Computer Society, 2016: 2818-2826. |
| 7 | CHOLLET F. Xception: deep learning with depthwise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE Computer Society, 2017: 1800-1807. |
| 8 | ZHANG Xiangyu, ZHOU Xinyu, LIN Mengxiao, et al. Shufflenet: an extremely efficient convolutional neural network for mobile devices[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE Computer Society, 2018: 6848-6856. |
| 9 | CHEN Liangchieh, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arXiv preprint arXiv: 1706.05587, 2017. https://arxiv.org/abs/1706.05587. |
| 10 | DUMOULIN V, VISIN F. A guide to convolution arithmetic for deep learning[J]. arXiv preprint arXiv: 1603.07285, 2016. https://arxiv.org/abs/1603.07285. |
| 11 | WEI S E, RAMAKRISHNA V, KANADE T, et al. Convolutional pose machines[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE Computer Society, 2016: 4724-4732. |
| 12 | CAO Xudong. A practical theory for designing very deep convolutional neural network[R/OL].[2018-08-01]. https://www.kaggle.com/c/datasciencebowl/discussion/13166. |
| 13 | YU Fisher, KOLTUN V. Multi-scale context aggregation by dilated convolutions[J]. arXiv preprint arXiv: 1511.07122, 2015. https://arxiv.org/abs/1511.07122. |
| 14 | WANG Panqu, CHEN Pengfei, YUAN Ye, et al. Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Nevada, USA: IEEE Computer Society, 2018: 1451-1460. |
| 15 | CHEN Liangchieh, ZHU Yukun, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[J]. arXiv preprint arXiv: 1802.02611, 2018. https://arxiv.org/abs/1802.02611 |
| 16 | REDMON J, FARHADI A. Yolo9000: better, faster, stronger[C]//Computer Vision and Pattern Recognition. Washington, USA: IEEE Computer Society, 2017: 6517-6525. |
| 17 | SHEN Zhiqiang, LIU Zhuang, LI Jianguo, et al. Dsod: learning deeply supervised object detectors from scratch[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, Italia: IEEE Computer Society, 2017: 1919-1927. |
| 18 | WANG R J, LI Xiang, LING C X. Pelee: a real-time object detection system on mobile devices[C]//Advances in Neural Information Processing Systems. Montreal, Canada: Neural Information Processing Sys-tems Foundation, Inc., 2018: 1963-1972. |
| 19 | LI Yuxi, LI Jiuwei, LIN Weiyao, et al. Tiny-dsod: lightweight object detection for resource-restricted usages[J]. arXiv preprint arXiv: 1807.11013, 2018. https://arxiv.org/abs/1807.11013. |
| 20 | ZOPH B, VASUDEVAN V, SHLENS J, et al. Learning transferable architectures for scalable image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE Computer Society, 2018: 8697-8710. |
| [1] | 严云洋,张慧珍,刘以安,高尚兵. 基于GMM与三维LBP纹理的视频火焰检测[J]. 山东大学学报 (工学版), 2019, 49(1): 1-9. |
|