山东大学学报 (工学版) ›› 2018, Vol. 48 ›› Issue (6): 8-18.doi: 10.6040/j.issn.1672-3961.0.2018.193
朱映雪1,2( ),黄瑞章1,2,*(),马灿1,2
),黄瑞章1,2,*(),马灿1,2
Yingxue ZHU1,2(),Ruizhang HUANG1,2,*(),Can MA1,2
摘要:
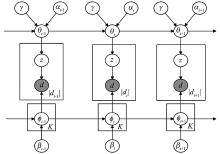
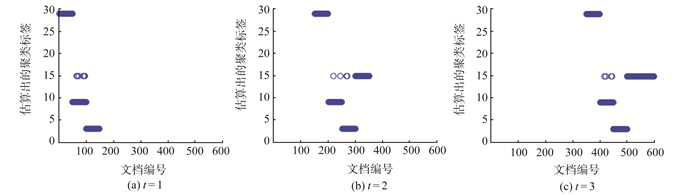
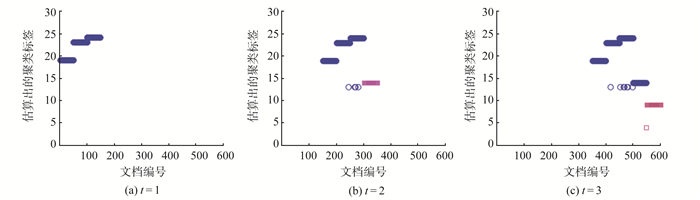
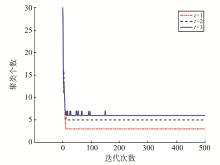
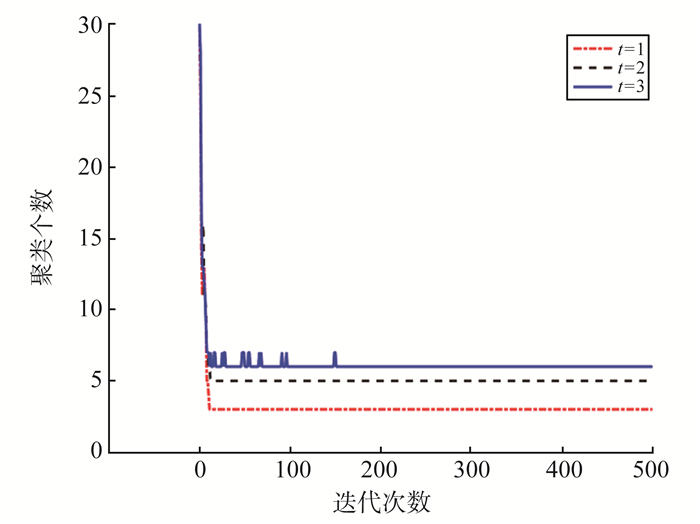
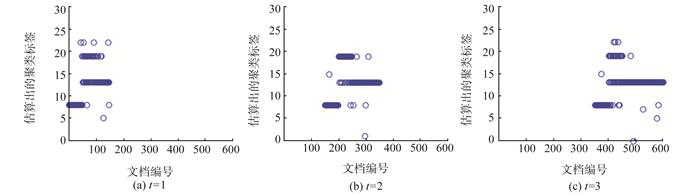
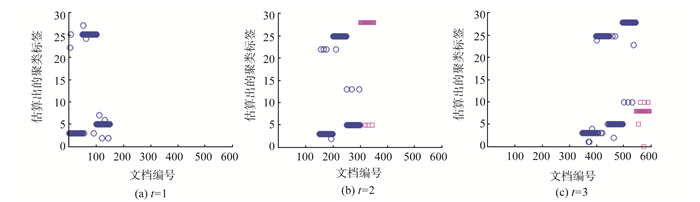
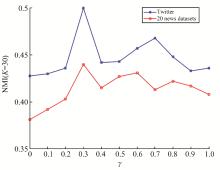
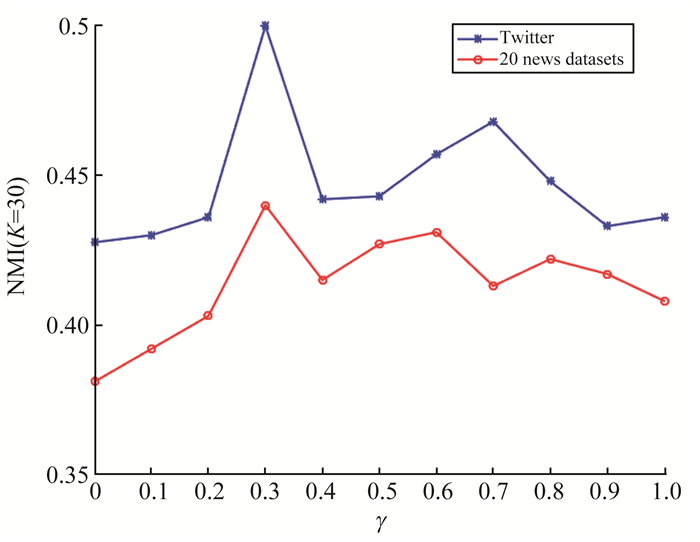
为了解决短文本数据流的动态聚类问题,提出动态的狄利克雷多项混合(dynamic Dirichlet multinomial mixture,DDMM)模型。模型能够很好地捕获短文本数据流中主题随时间变化而变化的动态过程,同时考虑到已有历史主题和新主题之间的关系,能够对主题继承性的强弱进行调整,从而增大新主题产生的可能。在Gibbs采样过程中,能够自动估算出聚类个数。模拟数据和真实数据上的试验表明,DDMM模型是有效的。同时将提出的方法和传统动态聚类方法进行对比,结果表明DDMM模型能够进行有效的文本动态聚类,并且聚类效果表现良好。
中图分类号:
| 1 | YIN J, WANG J.A Dirichlet multinomial mixture model-based approach for short text clustering[C]//Proc of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining: KDD'14.New York, USA: ACM, 2014: 233-242. |
| 2 | AHMED A, XING E P.Timeline: a dynamic hierarchical dirichlet process model for recovering birth/death and evolution of topics in text stream[C]//Proc of the 26th Conference on Uncertainty in Artificial Intelligence.New York, USA: AUAI Press, 2010: 20-29. |
| 3 | PITMAN J , YOR M . The two-parameter poisson dirichlet distribution derived from a stable subordinator[J]. Annals of Probability, 1995, 25 (2): 885- 900. |
| 4 | TEH Y W.A hierarchical bayesian language model based on pitman-yor processes[C]//Proc of the 21st Iternational Conference on Computational Linguistics and the Annual Meeting of the Association for Computational Linguistics.Sydney, Australia: ACM, 2006: 985-992. |
| 5 | PORTEOUS I, NEWMAN D, IHLER A, et al.Fast collapsed gibbs sampling for latent dirichlet allocation[C]//Proc of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Las Vegas, USA: ACM, 2008: 569-577. |
| 6 | BRUCE C , DONALD M , TREVOR S . Search engines: information retrieval in practice[M]. Boston, USA: Addison-Wesley, 2010: 22- 23. |
| 7 | HOFMANN T.Probabilistic latent semantic indexing[C]//Proc of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York, USA: ACM, 1999: 50-57. |
| 8 | BLEI D M , NG A Y , JORDAN M I . Latent dirichlet allocation[J]. The Journal of Machine Learning Research, 2003, 3, 993- 1022. |
| 9 | BLEID M, LAFFERTY J D.Dynamic topic models[C]//Proc of the 23rd International Conference on Machine Learning (ICML′06).New York, USA: ACM, 2006: 113-120. |
| 10 | WEI X, SUN J, WANG X.Dynamic mixture models for multiple time-Series[C]// Proc of the 20th International Joint Conference on Artificial Intelligence.Hyderabad, India: ACM, 2007: 2909-2914. |
| 11 | IWATA T, WATANABE S, YAMADA T, et al.Topic tracking model for analyzing consumer purchase behavior[C]//Proc of 21st International Joint Conference on Artificial Intelligence.San Francisco, USA: ACM, 2009: 1427-1432. |
| 12 | WANG X, MCCALLUM A.Topics over time: a non-markov continuous-time model of topical trends[C]//Proc of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York, USA: ACM, 2006: 424-433. |
| 13 |
李雷, 朱玉婷, 施化吉, 等. 社会网络中基于U_BTM模型的主题挖掘[J]. 计算机应用研究, 2017, 34 (1): 132- 135, 146.
doi: 10.3969/j.issn.1001-3695.2017.01.028 |
|
LI Lei , ZHU Yuting , SHI Huaji , et al. Topic mining based on U_BTM model in social networks[J]. Application Research of Computers, 2017, 34 (1): 132- 135, 146.
doi: 10.3969/j.issn.1001-3695.2017.01.028 |
|
| 14 | 谢珺, 郝洁, 苏婧琼, 等. 一种针对短文本的主题情感混合模型[J]. 中文信息学报, 2017, 31 (1): 162- 168. |
| XIE Jun , HAO Jie , SU Jingqiong , et al. A joint topic and sentiment model for short texts[J]. Journal of Chinese Information Processing, 2017, 31 (1): 162- 168. | |
| 15 | 刘泽锦, 王洁. 同主题词短文本分类算法中BTM的应用与改进[J]. 计算机系统应用, 2017, 26 (11): 213- 219. |
| LIU Zejin , WANG Jie . Application and improvement of BTM in short text classification algorithm of the same topic[J]. Computer Systems & Applications, 2017, 26 (11): 213- 219. | |
| 16 | YAN X, GUO J, LAN Y, et al.A biterm topic model for short texts[C]//Proc of the 22nd International Conference on World Wide Web.New York, USA: ACM, 2013: 1445-1456. |
| 17 |
ZHOU X , OUYANG J , LI X . Two time-efficient gibbs sampling inference algorithms for biterm topic model[J]. Applied Intelligence, 2018, 48 (3): 730- 754.
doi: 10.1007/s10489-017-1004-2 |
| 18 |
CHENG X , YAN X , LAN Y , et al. BTM:topic modeling over short texts[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26 (12): 2928- 2941.
doi: 10.1109/TKDE.2014.2313872 |
| 19 | WANG Y, AGICHTEIN E, BENZI M.TM-LDA: efficient online modeling of latent topic transitions in social media[C]//Proc of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ′12).New York, USA: ACM, 2012: 123-131. |
| 20 | ZHAO W X , JIANG J , WENG J , et al. Comparing twitter and traditional media using topic models[J]. Berlin, Germany: Springer, 2011, 338- 349. |
| 21 | SASAKI K, YOSHIKAWA T, FURUHASHI T.Online topic model for twitter considering dynamics of user interests and topic trends[C] //Proc of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics.Doha, Qatar: ACL, 2014: 1977-1985. |
| 22 | LIANG S, YILMAZ E, KANOULAS E.Dynamic clustering of streaming short documents[C]//Proc of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD′16).New York, USA: ACM, 2016: 995-1004. |
| 23 | LIANG S, REN Z, YILMAZ E, et al.Collaborative user clustering for short text streams[C]//Proc of the 31st AAAI Conference on Artificial Intelligence.San Francisco, USA: ACM, 2017: 3504-3510. |
| 24 | 刘冰玉, 王翠荣, 王聪, 等. 基于动态主题模型融合多维数据的微博社区发现算法[J]. 软件学报, 2017, 28 (2): 246- 261. |
| LIU Bingyu , WANG Cuirong , WANG Cong , et al. Microblog community discovery algorithm based on dynamic topic model with multidimensional data fusion[J]. Journal of Software, 2017, 28 (2): 246- 261. | |
| 25 | PHADIA E G . Prior processes and their applications[M]. New York, USA: Springer, 2016: 77- 79. |
| 26 | ZHONG S . Semi-supervised model-based document clustering: a comparative study[J]. Machine Learning, 2006, 65 (3): 3- 29. |
| 27 |
TEH Y W , JORDAN M I , BEAL M J , et al. Hierarchical dirichlet process[J]. Journal of American Statistical Association, 2006, 101 (476): 1566- 1581.
doi: 10.1198/016214506000000302 |
| [1] | 闫盈盈,黄瑞章,王瑞,马灿,刘博伟,黄庭. 一种长文本辅助短文本的文本理解方法[J]. 山东大学学报(工学版), 2018, 48(3): 67-74. |
| [2] | 卢文羊, 徐佳一, 杨育彬. 基于LDA主题模型的社会网络链接预测[J]. 山东大学学报(工学版), 2014, 44(6): 26-31. |
|