山东大学学报 (工学版) ›› 2019, Vol. 49 ›› Issue (6): 25-35.doi: 10.6040/j.issn.1672-3961.0.2019.244
常致富( ),周风余*(),王玉刚,沈冬冬,赵阳
),周风余*(),王玉刚,沈冬冬,赵阳
Zhifu CHANG(),Fengyu ZHOU*(),Yugang WANG,Dongdong SHEN,Yang ZHAO
摘要:
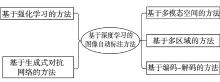
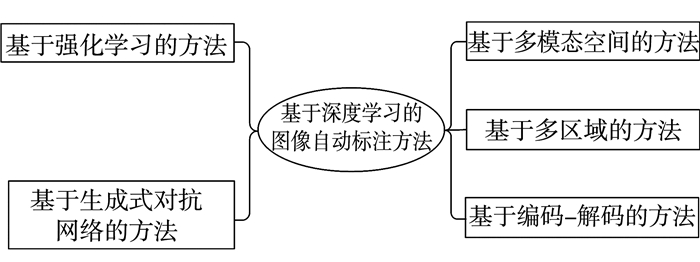
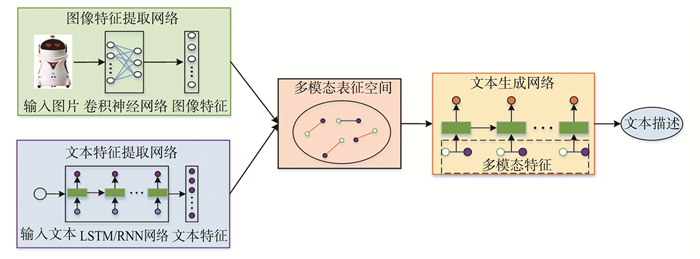
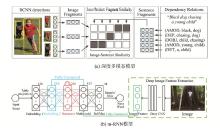
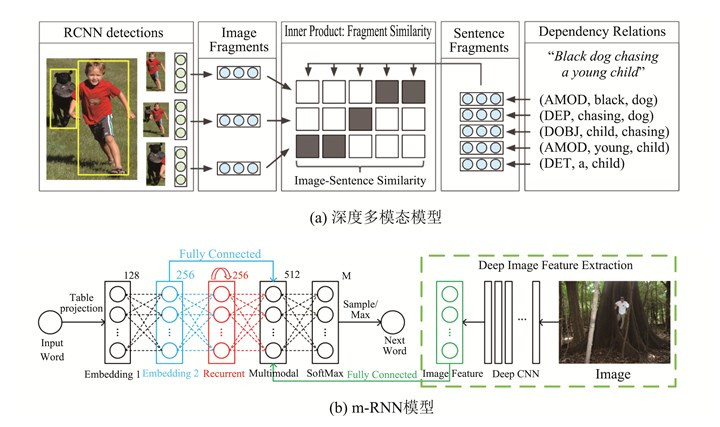
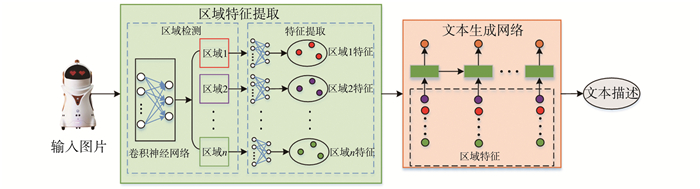
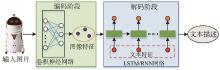
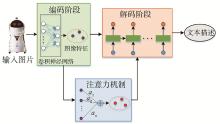
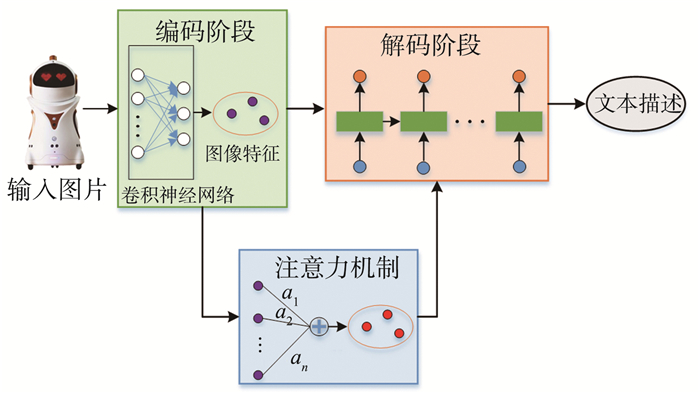
图像自动标注是目前计算机视觉和自然语言处理交叉研究领域的一个研究热点。对图像自动标注领域中的深度学习方法进行综述;针对图像自动标注领域的国内外研究现状,按照基于多模态空间、基于多区域、基于编码-解码、基于强化学习和基于生成式对抗网络等五个分类标准进行详细综述;介绍图像自动标注领域相关的数据集和评价标准,对比不同图像自动标注方法的优缺点;通过分析图像自动标注领域的当前研究现状,提出该领域亟待解决的3个关键问题,进一步指出未来的研究方向,并对本研究进行总结。
中图分类号:
| 1 | LI F F , IYER A , KOCH C , et al. What do we perceive in a glance of a real-world scene[J]. Journal of Vision, 2007, 7 (1): 10- 10. |
| 2 | KARPATHY A, LI F F.Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Boston, USA: IEEE, 2015: 3128-3137. |
| 3 | HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on imagenet classification[C]//Proceedings of the IEEE International Conference on Computer Vision.Santiago, Chile: IEEE, 2015: 1026-1034. |
| 4 | REN S, HE K, GIRSHICK R, et al. Faster r-cnn: towards real-time object detection with region proposal networks[C]//Advances in Neural Information Processing Systems. Montreal, Canada: NIPS, 2015: 91-99. |
| 5 | SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[C]//Advances in Neural Information Processing Systems. Montreal, Canada: NIPS, 2014: 3104-3112. |
| 6 | HOSSAIN M , SOHEL F , SHIRATUDDIN M F , et al. A comprehensive study of deep learning for image captioning[J]. Arxiv: Computer Vision and Pattern Recognition, 2018. |
| 7 | FU K , LI J , JIN J , et al. Image-text surgery:efficient concept learning in image captioning by generating pseudopairs[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, (99): 1- 12. |
| 8 | GAO L, FAN K, SONG J, et al.Deliberate attention networks for image captioning[C]//AAAI-19. Honolulu, USA: AAAI, 2019: 8320-8327. |
| 9 | CHEN F, JI R, SUN X, et al. Groupcap: group-based image captioning with structured relevance and diversity constraints[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 1345-1353. |
| 10 | 彭宇新, 綦金玮, 黄鑫. 多媒体内容理解的研究现状与展望[J]. 计算机研究与发展, 2019, 56 (1): 183- 208. |
| PENG Y X , QI J W , HUANG X . Current research status and prospects on multimedia content understanding[J]. Journal of Computer Research and Development, 2019, 56 (1): 183- 208. | |
| 11 | FARHADI A, HEJRATI M, SADEGHI M A, et al. Every picture tells a story: generating sentences from images[C]//European Conference on Computer Vision. Berlin, Germany: Springer, 2010: 15-29. |
| 12 | ORDONEZ V, KULKARNI G, BERG T L. Im2text: describing images using 1 million captioned photographs[C]//Advances in Neural Information Processing Systems. Granada, Spain: Curran Associates Inc, 2011: 1143-1151. |
| 13 | YANG Y, TEO C L, DAUMÉ H, et al. Corpus-guided sentence generation of natural images[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Edinburgh, United Kingdom: ACL, 2011: 444-454. |
| 14 | LI S, KULKARNI G, BERG T L, et al. Composing simple image descriptions using web-scale n-grams[C]//Proceedings of the Fifteenth Conference on Computa-tional Natural Language Learning. Portland, USA: ACL, 2011: 220-228. |
| 15 |
LECUN Y , BENGIO Y , HINTON G . Deep learning[J]. Nature, 2015, 521 (7553): 436.
doi: 10.1038/nature14539 |
| 16 | KIROS R, SALAKHUTDINOV R, ZEMEL R. Multimodal neural language models[C]//International Conference on Machine Learning. Beijing, China: IMLS, 2014: 595-603. |
| 17 | KARPATHY A, JOULIN A, LI F F. Deep fragment embeddings for bidirectional image sentence mapping[C]//Advances in Neural Information Processing Systems. Montreal, Canada: NIPS, 2014: 1889-1897. |
| 18 | MAO J , XU W , YANG Y , et al. Deep captioning with multimodal recurrent neural networks (m-rnn)[J]. Arxiv: Computer Vision and Pattern Recognition, 2014. |
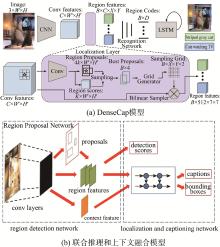
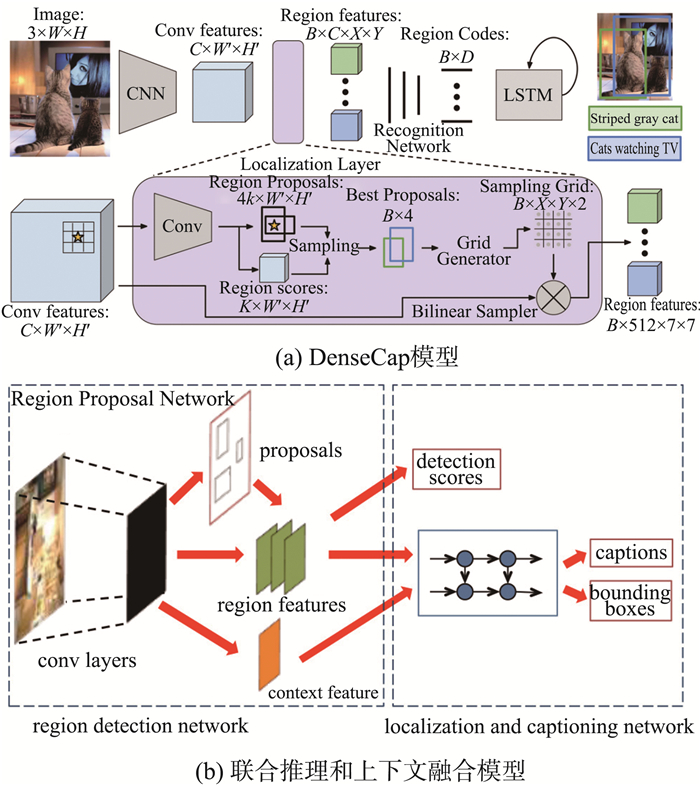
| 19 | JOHNSON J, KARPATHY A, LI F F. Densecap: fully convolutional localization networks for dense captioning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 4565-4574. |
| 20 | YANG L, TANG K, YANG J, et al. Dense captioning with joint inference and visual context[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 2193-2202. |
| 21 | KRISHNA R , ZHU Y , GROTH O , et al. Visual genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123 (1): 32- 73. |
| 22 | CHO K , VAN MERRI NBOER B , GULCEHRE C , et al. Learning phrase representations using rnn encoder-decoder for statistical machine translation[J]. Arxiv: Computer Vision and Pattern Recognition, 2014. |
| 23 | VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: a neural image caption generator[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015: 3156-3164. |
| 24 | JIA X, GAVVES E, FERNANDO B, et al. Guiding the long-short term memory model for image caption generation[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 2407-2415. |
| 25 | MAO J, HUANG J, TOSHEV A, et al. Generation and comprehension of unambiguous object descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 11-20. |
| 26 | WANG C, YANG H, BARTZ C, et al. Image captioning with deep bidirectional LSTMs[C]//Proceedings of the 2016 ACM on Multimedia Conference. Amsterdam, United Kingdom: ACM, 2016: 988-997. |
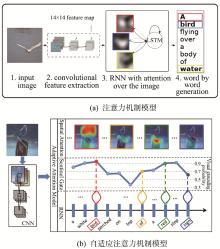
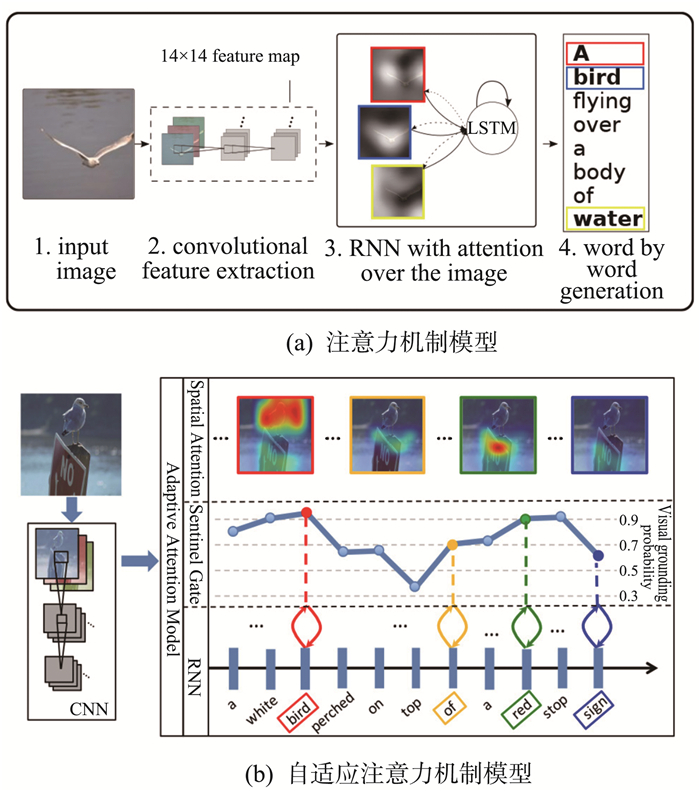
| 27 | XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention[C]//International Conference on Machine Learning.Lile, France: IMLS, 2015: 2048-2057. |
| 28 | LU J, XIONG C, PARIKH D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 375-383. |
| 29 | PEDERSOLI M, LUCAS T, SCHMID C, et al. Areas of attention for image captioning[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 1242-1250. |
| 30 | TAVAKOLI H R, SHETTY R, BORJI A, et al. Paying attention to descriptions generated by image captioning models[C]//Proceedings of the IEEE International Conference on Computer Vision.Venice, Italy: IEEE, 2017: 2487-2496. |
| 31 | ANDERSON P, HE X, BUEHLER C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 6077-6086. |
| 32 | CHUNSEONG Park C, KIM B, KIM G. Attend to you: personalized image captioning with context sequence memory networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 895-903. |
| 33 | YOU Q, JIN H, WANG Z, et al. Image captioning with semantic attention[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 4651-4659. |
| 34 | YAO T, PAN Y, LI Y, et al. Boosting image captioning with attributes[C]//Proceedings of the IEEE International Conference on Computer Vision.Venice, Italy: IEEE, 2017: 4894-4902. |
| 35 | REN Z, WANG X, ZHANG N, et al. Deep reinforcement learning-based image captioning with embedding reward[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017: 1151-1159. |
| 36 | RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu, USA: IEEE, 2017: 7008-7024. |
| 37 | ZHANG L , SUNG F , LIU F , et al. Actor-critic sequence training for image captioning[J]. Arxiv: Computer Vision and Pattern Recognition, 2017. |
| 38 | KONDA V R, TSITSIKLIS J N. Actor-critic algorithms[C]//Advances in Neural Information Processing Systems. Denver, USA: NIPS, 2000: 1008-1014. |
| 39 | DAI B , FIDLER S , URTASUN R , et al. Towards diverse and natural image descriptions via a conditional gan[J]. Arxiv: Computer Vision and Pattern Recognition, 2017. |
| 40 | SHETTY R, ROHRBACH M, HENDRICKS L A, et al. Speaking the same language: matching machine to human captions by adversarial training[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017: 4155-4164. |
| 41 | LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context[C]//European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014: 740-755. |
| 42 |
HODOSH M , YOUNG P , HOCKENMAIER J . Framing image description as a ranking task: data, models and evaluation metrics[J]. Journal of Artificial Intelligence Research, 2013, 47, 853- 899.
doi: 10.1613/jair.3994 |
| 43 | PLUMMER B A, WANG L, CERVANTES C M, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 2641-2649. |
| 44 | GRUBINGER M, CLOUGH P, MVLLER H, et al. The iapr tc-12 benchmark: a new evaluation resource for visual inform-ation systems[C]//International Workshop Ontoimage. Genoa, Italy: OntoImage, 2006: 13-55. |
| 45 | BYCHKOVSKY V, PARIS S, CHAN E, et al. Learning photographic global tonal adjustment with a database of input/output image pairs[C]//CVPR 2011. Piscataway, USA: IEEE, 2011: 97-104. |
| 46 | PAPINENI K, ROUKOS S, WARD T, et al. Bleu: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Istanbul, Turkey: ACL, 2002: 311-318. |
| 47 | LIN C Y . Rouge: a package for automatic evaluation of summaries[J]. Text Summarization Branches Out, 2004, 74- 81. |
| 48 | BANERJEE S, LAVIE A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments[C]//Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Istanbul, Turkey: ACL, 2005: 65-72. |
| 49 | VEDANTAM R, LAWRENCE ZITNICK C, Parikh D. Cider: consensus-based image description evaluation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015: 4566-4575. |
| 50 | ANDERSON P, FERNANDO B, JOHNSON M, et al. Spice: semantic propositional image caption evaluation[C]//Euopean Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016: 382-398. |
| 51 | GAN Z, GAN C, HE X, et al. Semantic compositional networks for visual captioning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 5630-5639. |
| 52 | GU J, WANG G, CAI J, et al. An empirical study of language cnn for image captioning[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 1222-1231. |
| [1] | 高君健,廖祝华,刘毅志,赵肄江. 基于分层多智能体强化学习的个性化与信号控制联合路径引导方法[J]. 山东大学学报 (工学版), 2025, 55(3): 34-45. |
| [2] | 陈兴国,吕咏洲,巩宇,陈耀雄. 基于贝叶斯优化的强化学习广义不动点解逼近[J]. 山东大学学报 (工学版), 2024, 54(4): 21-34. |
| [3] | 曹宇慧,黄昱泽,冯北鹏,张淼,郭珍珍. 基于深度强化学习的物联网服务协同卸载方法[J]. 山东大学学报 (工学版), 2024, 54(1): 83-90. |
| [4] | 张俊三,程俏俏,万瑶,朱杰,张世栋. MIRGAN: 一种基于GAN的医学影像报告生成模型[J]. 山东大学学报 (工学版), 2021, 51(2): 9-18. |
| [5] | 朱娜娜1, 2, 张化祥1, 2*, 刘丽1, 2. 基于改进FCM算法和贝叶斯分类的图像自动标注[J]. 山东大学学报(工学版), 2013, 43(6): 12-16. |
| [6] | 沈晶,刘海波,张汝波,吴艳霞,程晓北. 基于半马尔可夫对策的多机器人分层强化学习[J]. 山东大学学报(工学版), 2010, 40(4): 1-7. |
|